Abstract
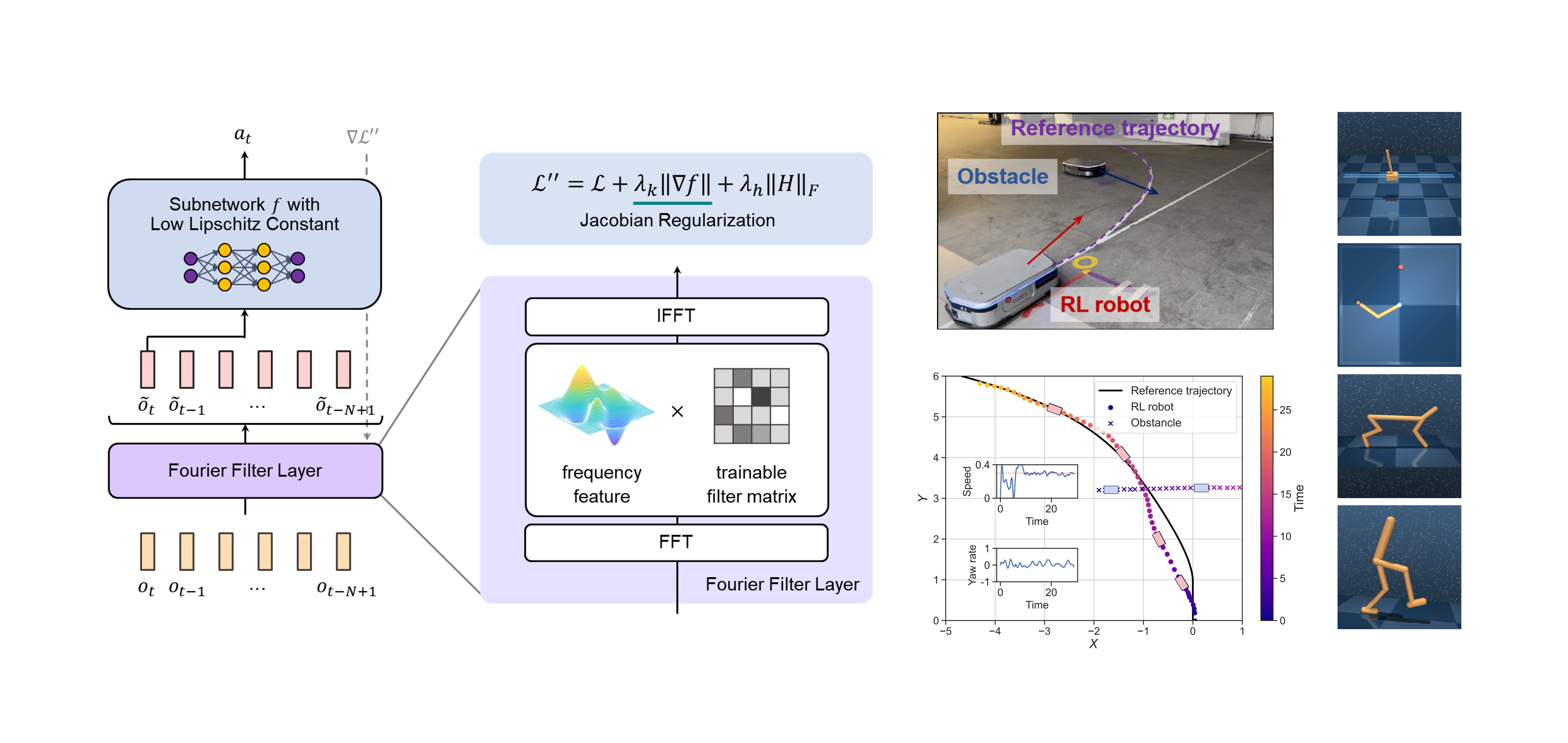
Deep reinforcement learning (RL) is an effective approach for decision-making and control tasks. However, RL-trained policy networks often suffer from the action fluctuation problem in real-world applications, resulting in severe actuator wear, safety risk, and performance degradation. In this paper, we identified the two fundamental causes of action fluctuation — observation noise and policy non-smoothness. Then, we propose a novel policy network, LipsNet++, integrating a Fourier filter layer and a Lipschitz controller layer to mitigate these two causes decoupledly. The filter layer incorporates a trainable filter matrix that automatically extracts important frequencies while suppressing noise frequencies in the observations. The controller layer introduces a Jacobian regularization technique to achieve a low Lipschitz constant, ensuring smooth fitting of a policy function. These two layers function analogously to the filter and controller in classical control theory, suggesting that filtering and control capabilities can be seamlessly integrated into a single policy network. Both simulated and real-world experiments demonstrate that LipsNet++ achieves the state-of-the-art noise robustness and action smoothness.