Abstract
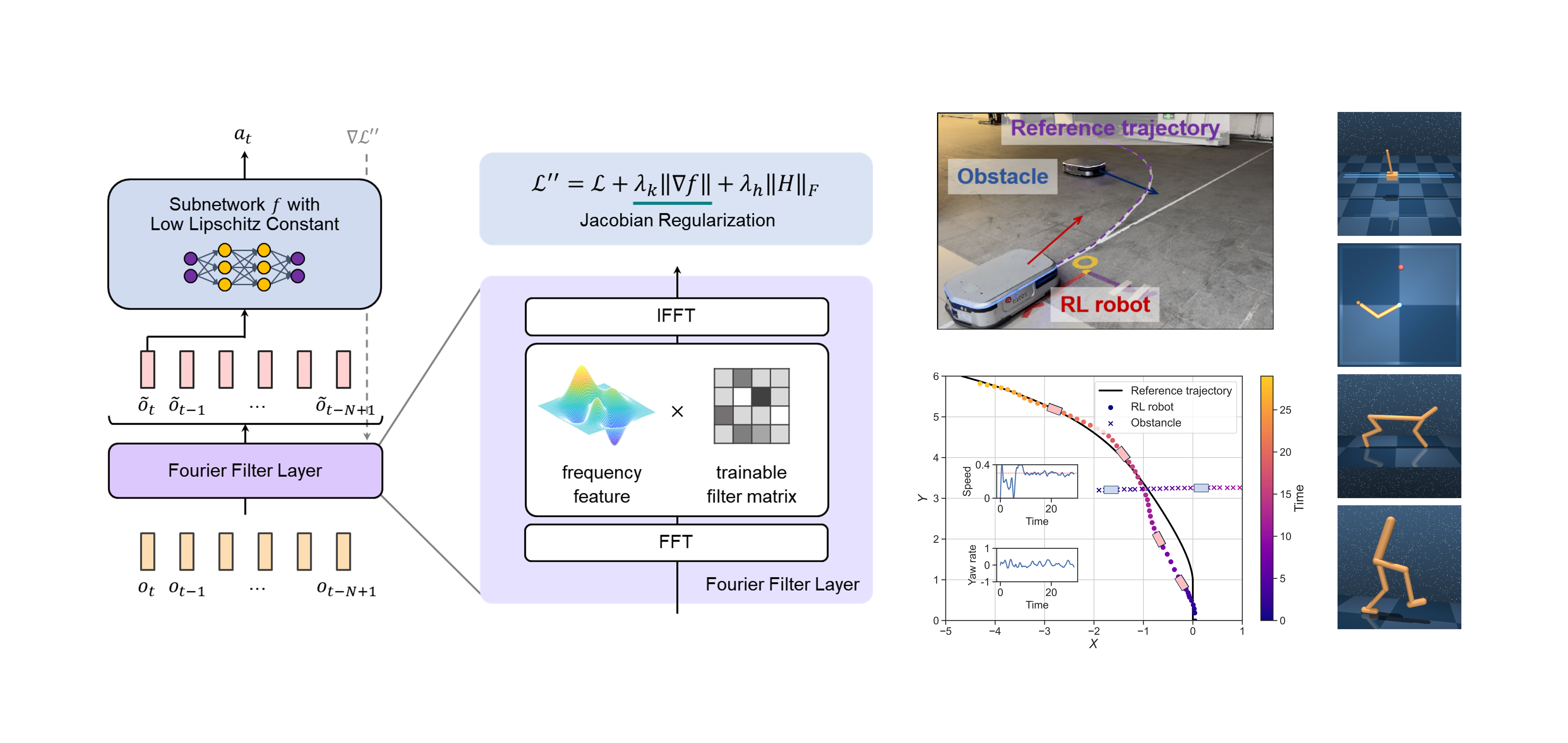
Deep reinforcement learning (RL) is an effective method for decision-making and control tasks. However, RL-trained policies encounter the action fluctuation problem, where consecutive actions significantly differ despite minor variations in adjacent states. This problem results in actuators’ wear, safety risk, and performance reduction in real-world applications. To address the problem, we identify the two fundamental reasons causing action fluctuation, i.e. policy non-smoothness and observation noise, then propose the Fourier Lipschitz Smooth Policy Network (FlipNet). FlipNet adopts two innovative techniques to tackle the two reasons in a decoupled manner. Firstly, we prove the Jacobian norm is an approximation of Lipschitz constant and introduce a Jacobian regularization technique to enhance the smoothness of policy network. Secondly, we introduce a Fourier filter layer to deal with observation noise. The filter layer includes a trainable filter matrix that can automatically extract important observation frequencies and suppress noise frequencies. FlipNet can be seamlessly integrated into most existing RL algorithms as an actor network. Simulated tasks on DMControl and a real-world experiment on vehicle-robot driving show that FlipeNet has excellent action smoothness and noise robustness, achieving a new state-of-the-art performance. The code and videos are publicly available.